The post Serverless Compute Need Serverless Storage appeared first on simplyblock.
]]>Due to this movement, other cloud operators, many database companies (such as Neon and Nile), and infrastructure teams at large enterprises are building serverless environments, either on their premises or in their private cloud platforms.
While there are great options for serverless compute, providing serverless storage to your serverless platform tends to be more challenging. This is often fueled by a lack of understanding of what serverless storage has to provide and its requirements.
What is a Serverless Architecture?
Serverless architecture is a software design pattern that leverages serverless computing resources to build and run applications without managing the underlying architecture. These serverless compute resources are commonly provided by cloud providers such as AWS Lambda, Google Cloud Functions, or Azure Functions and can be dynamically scaled up and down.
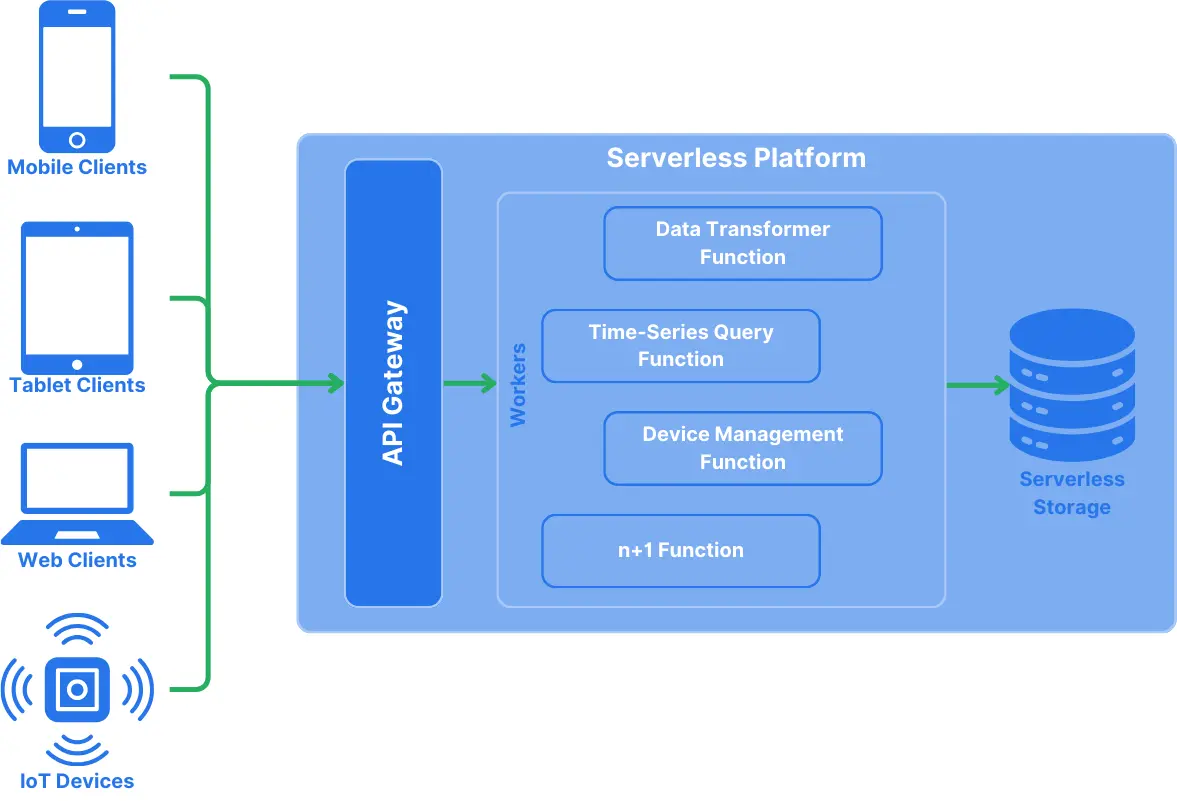
When designing a serverless architecture, you’ll encounter the so-called Function-as-a-Service (FaaS), meaning that the application’s core logic will be implemented in small, stateless functions that respond to events.
That said, typically, several FaaS make up the actual application, sending events between them. Since the underlying infrastructure is abstracted away, the functions don’t know how requests or responses are handled, and their implementations are designed for vendor lock-in and built against a cloud-provider-specific API.
Cloud-vendor-agnostic solutions exist, such as knative, but require at least parts of the team to manage the Kubernetes infrastructure. They can, however, take the burden away from other internal and external development teams.
What is Serverless Compute?
While a serverless architecture describes the application design that runs on top of a serverless compute infrastructure, serverless compute itself describes the cloud computing model in which the cloud provider dynamically manages the allocation and provisioning of server resources.
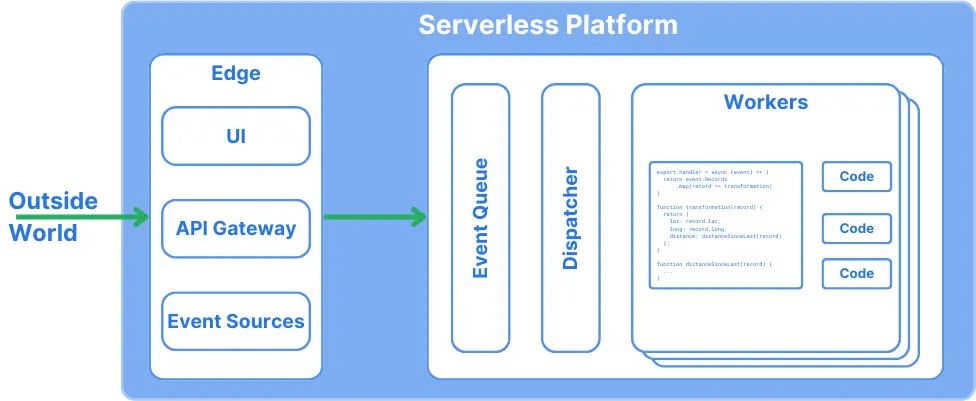
It is essential to understand that serverless doesn’t mean “without servers” but “as a user, I don’t have to plan, provision, or manage the infrastructure.”
In essence, the cloud provider (or whoever manages the serverless infrastructure) takes the burden from the developer. Serverless compute environments fully auto-scale, starting or stopping instances of the functions according to the needed capacity. Due to their stateless nature, it’s easy to stop and restart them at any point in time. That means that function instances are often very short-lived.
Popular serverless compute platforms include AWS Lambda, Google Cloud Functions, and Azure Functions. For self-managed operations, there is knative (mentioned before), as well as OpenFaaS and OpenFunction (which seems to have less activity in the recent future).
They all enable developers to focus on writing code without managing the underlying infrastructure.
What is a Serverless Storage System?
Serverless storage refers to a cloud storage model where the underlying infrastructure, capacity planning, and scaling are abstracted away from the user. With serverless storage, customers don’t have to worry about provisioning or managing storage servers or volumes. Instead, they can store and retrieve data while the serverless storage handles all the backend infrastructure.
Serverless storage solutions come in different forms and shapes, beginning with an object storage interface, such as Amazon S3 or Google Cloud Storage. Object storage is excellent when storing unstructured data, such as documents or media.
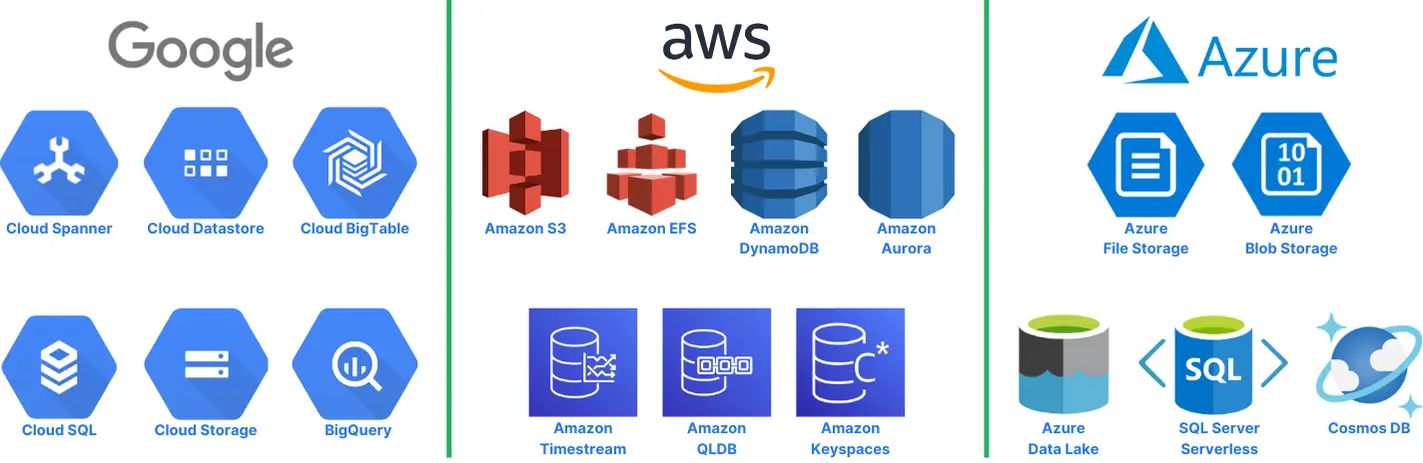
Another option that people love to use for serverless storage is serverless databases. Various options are available, depending on your needs: relational, NoSQL, time-series, and graph databases. This might be the easiest way to go, depending on how you need to access data. Examples of such serverless databases include Amazon Aurora Serverless, Google’s Cloud Datastore, and external companies such as Neon or Nile.
When self-managing your serverless infrastructure with knative or one of the alternative options, you can use Kubernetes CSI storage providers to provide storage into your functions. However, you may add considerable startup time if you choose the wrong CSI driver. I might be biased, but simplyblock is an excellent option with its neglectable provisioning and attachment times, as well as features such as multi-attach, where a volume can be attached to multiple functions (for example, to provide a shared set of data).
Why Serverless Architectures?
Most people think of cost-efficiency when it comes to serverless architectures. However, this is only one side of the coin. If your use cases aren’t a good fit for a serverless environment, it will hold true—more on when serverless makes sense later.
In serverless architectures, functions are triggered through an event, either from the outside world (like an HTTP request) or an event initiated by another function. If no function instance is up and running, a new instance will be started. The same goes for situations where all function instances are busy. If function instances idle, they’ll be shut down.
Serverless functions usually use a pay-per-use model. A function’s extremely short lifespan can lead to cost reductions over deployment models like containers and virtual machines, which tend to run longer.
Apart from that, serverless architectures have more benefits. Many are moving in the same direction as microservices architectures, but with the premise that they are easier to implement and maintain.
First and foremost, serverless solutions are designed for scalability and elasticity. They quickly and automatically scale up and down depending on the incoming workload. It’s all hands-free.
Another benefit is that development cycles are often shortened. Due to the limited size and functionality of a FaaS, changes are fast to implement and easy to test. Additionally, updating the function is as simple as deploying the new version. All existing function instances finish their current work and shut down. In the meantime, the latest version will be started up. Due to its stateless nature, this is easy to achieve.
What are the Complexities of Serverless Architecture?
Writing serverless solutions has the benefits of fast iteration, simplified deployments, and potential cost savings. However, they also come with their own set of complexities.
Designing real stateless code isn’t easy, at least when we’re not just talking about simple transformation functionality. That’s why a FaaS receives and passes context information along during its events.
What works great for small bits of context is challenging for larger pieces. In this situation, a larger context, or state, can mean lots of things, starting from simple cross-request information that should be available without transferring it with every request over more involved data, such as lookup information to enrich and cross-check, all the way to actual complex data, like when you want to implement a serverless database. And yes, a serverless database needs to store its data somewhere.
That’s where serverless storage comes in, and simply put, this is why all serverless solutions have state storage alternatives.
What is Serverless Storage?
Serverless storage refers to storage solutions that are fully integrated into serverless compute environments without manual intervention. These solutions scale and grow according to user demand and complement the pay-by-use payment model of serverless platforms.
Serverless storage lets you store information across multiple requests or functions.
As mentioned above, cloud environments offer a wide selection of serverless storage options. However, all of them are vendor-bound and lock you into their services.
However, when you design your serverless infrastructure or service, these services don’t help you. It’s up to you to provide the serverless storage. In this case, a cloud-native and serverless-supporting storage engine can simplify this talk immensely. Whether you want to provide object storage, a serverless database, or file-based storage, an underlying cloud-native block storage solution is the perfect building block underneath. However, this block storage solution needs to be able to scale and grow with your needs easily and quickly to provision and support snapshotting, cloning, and attaching to multiple function instances.
Why do Serverless Architectures Require Serverless Storage?
Serverless storage has particular properties designed for serverless environments. It needs to keep up with the specific requirements of serverless architectures, most specifically short lifetimes, extremely fast up and down scaling or restarts, easy use across multiple versions during updates, and easy integration through APIs utilized by the FaaS.
The most significant issues are that it must be used by multiple function instances simultaneously and is quickly available to new instances on other nodes, regardless of whether those are migrated over or used for scaling out. That means that the underlying storage technology must be prepared to handle these tasks easily.
These are just the most significant requirements, but there are more:
- Stateless nature: Serverless functions spin up, execute, and terminate due to their stateless nature. Without fast, persistent storage that can be attached or accessed without any additional delay, this fundamental property of serverless functions would become a struggle.
- Scalability needs: Serverless compute is built to scale automatically based on user demand. A storage layer needs to seamlessly support the growth and shrinking of serverless infrastructures and handle variations in I/O patterns, meaning that traditional storage systems with fixed capacity limits don’t align well with the requirements of serverless workloads.
- Cost efficiency: One reason people engage with serverless compute solutions is cost efficiency. Serverless compute users pay by actual execution time. That means that serverless storage must support similar payment structures and help serverless infrastructure operators efficiently manage and scale their storage capacities and performance characteristics.
- Management overhead: Serverless compute environments are designed to eliminate manual server management. Therefore, the storage solution needs to minimize its manual administrative tasks. Allocating and scaling storage requirements must be fully integratable and automated via API calls or fully automatic. Also, the integration must be seamless if multiple storage tiers are available for additional cost savings.
- Performance requirements: Serverless functions require fast, if not immediate, access to data when they spin up. Traditional storage solutions introduce delays due to allocation and additional latency, negatively impacting serverless functions’ performance. As functions are paid by runtime, their operational cost increases.
- Integration needs: Serverless architectures typically combine many services, as individual functions use different services. That said, the underlying storage solution of a serverless environment needs to support all kinds of services provided to users. Additionally, seamless integration with the management services of the serverless platform is required.
There are quite some requirements. For the alignment of serverless compute and serverless storage, storage solutions need to provide an efficient and manageable layer that seamlessly integrates with the overall management layer of the serverless platform.
Simplyblock for Serverless Storage
When designing a serverless environment, the storage layer must be designed to keep up with the pace. Simplyblock enables serverless infrastructures to provide dynamic and scalable storage.
To achieve this, simplyblock provides several characteristics that perfectly align with serverless principles:
- Dynamic resource allocation: Simplyblock’s thin provisioning makes capacity planning irrelevant. Storage is allocated on-demand as data is written, similar to how serverless platforms allocate resources. That means every volume can be arbitrarily large to accommodate unpredictable future growth. Additionally, simplyblock’s logical volumes are resizable, meaning that the volume can be enlarged at any point in the future.
- Automatic scaling: Simplyblock’s storage engine can indefinitely grow. To acquire additional backend storage, simplyblock can automatically acquire additional persistent disks (like Amazon EBS volumes) from cloud providers or attach additional storage nodes to its cluster when capacity is about to exceed, handling scaling without user intervention.
- Abstraction of infrastructure: Users interact with simplyblock’s virtual drives like normal hard disks. This abstracts away the complexity of the underlying storage pooling and backend storage technologies.
- Unified interface: Simplyblock provides a unified storage interface (NVMe) logical device that abstracts away underlying, diverging storage interfaces behind an easy-to-understand disk design. That enables services not specifically designed to talk to object storages or similar technologies to immediately benefit from them, just like PostgreSQL or MySQL.
- Extensibility: Due to its disk-like storage interface, simplyblock is highly extensible in terms of solutions that can be run on top of it. Databases, object storage, file storage, and specific storage APIs, simplyblock provides scalable block storage to all of them, making it the perfect backend solution for serverless environments.
- Crash-consistent and recoverable: Serverless storage must always be up and running. Simplyblock’s distributed erasure coding (parity information similar to RAID-5 or 6) enables high availability and fault tolerance on the storage level with a high storage efficiency, way below simple replication. Additionally, simplyblock provides storage cluster replication (sync / async), consistent snapshots across multiple logical volumes, and disaster recovery options.
- Automated management: With features like automatic storage tiering to cheaper object storage (such as Amazon S3), automatic scaling, as well as erasure coding and backups for data protection, simplyblock eliminates manual management overhead and hands-on tasks. Simplyblock clusters are fully autonomous and manage the underlying storage backend automatically.
- Flexible integration: Serverless platforms require storage to be seamlessly allocated and provisioned. Simplyblock achieves this through its API, which can be integrated into the standard provisioning flow of new customer sign-ups. If the new infrastructure runs on Kubernetes, integration is even easier with the Kubernetes CSI driver, allowing seamless integration with container-based serverless platforms such as knative.
- Pay-per-use potential: Due to the automatic scalability, thin provisioning, and seamless resizing and integration, simplyblock enables you to provide your customers with an industry-loved pay-by-use model for managed service providers, perfectly aligning with the most common serverless pricing models.
Simplyblock is the perfect backend storage for all your serverless storage needs while future-proofing your infrastructure. As data grows and evolves, simplyblock’s flexibility and scalability ensure you can adapt without massive overhauls or migrations.
Remember, simplyblock offers powerful features like thin provisioning, storage pooling, and tiering, helping you to provide a cost-efficient, pay-by-use enabled storage solution. Get started now and find out how easy it is to operate services on top of simplyblock.
The post Serverless Compute Need Serverless Storage appeared first on simplyblock.
]]>